Current status and achievements
- We created the uncensored model for all Venice.ai users (Venice is generating ~60k prompts per hour for over 1m total users) - Dolphin Mistral 24B Venice Edition .
- Over 5m monthly downloads of our models on Hugging Face.
- Dolphin Inference Network v1 is now live - https://x.com/dphnAI/status/1978158402431041657
Summary
This webpage is split into 4 sections
Dolphin AI Models
Dolphin is trained on top of leading open-source frontier models with the goal of customizing alignment to the user.
We have developed a pipeline to create Uncensored, Unaligned & Unbiased versions of the best open-source AI models that are available to the public.
Dolphin has produced its own versions of Meta's Llama 3, Mistral & Mixtral MoE, Google's Gemma, Alibaba's Qwen 3 & other popular models.
This is done through a process called "fine tuning" which modifies the base model using a custom dataset.
When creating our dataset, we identify and remove as many refusals and biased answers as possible and keep the rest.
The model is then trained with the filtered dataset the same way that the original instruct model was trained, producing a much more compliant version of the base model that should not refuse any of the user's requests.
We aim to retain all the intelligence of the base model throughout this process, while also expanding the knowledge base with our coding and math-focused datasets. Ultimately, this will create a model that can respond to almost any prompt you can imagine.
Dolphin models are also trained to produce desirable prose in the response style, ensuring they are both entertaining and highly informative.
Model lineup
- Dolphin X1 - uncensored by default while keeping the base model's skills and intelligence.
- Dolphin RP - creative, role-playing models suited for personas and storytelling.
- Dolphin S1 - steerable alignment level via request-time flags.
Dolphin Mistral 24B Venice Edition, trained on Mistral Small 24B
https://x.com/AskVenice/status/1917001067071410661
Dolphin X1 8B, trained on
Llama3.1 8B
https://x.com/dphnAI/status/1977769183992852835
Dolphin X1 405B, trained on
Llama-3.1-Tulu-3-405B
https://x.com/dphnAI/status/1986790436661534881
Dolphin Yi 34B, trained on Yi
1.5 34B (Chinese model) - over 4.6m monthly downloads
https://huggingface.co/dphn/dolphin-2.9.1-yi-1.5-34b
Read more about how we trained Dolphin 405B with a single B200 node here in our first blog post.
Dolphin 8B and 24B are both available to use in our chat UI at chat.dphn.ai or our Telegram bot @DolphinAI_bot.
Why use Dolphin AI models over ChatGPT or Claude
The reason these models are aligned is that they are trained with data that was generated by ChatGPT, which itself is aligned by an alignment team at OpenAI.
As it is a black box, we don't know all the reasons for the decisions that were made, but we can observe it generally is aligned with American popular culture, and to obey American law, and with a liberal and progressive political bias.
Dolphin aims to put alignment in the hands of the user, without artificially restricting what prompts will or will not be answered by the model while ChatGPT answers like this:
I'm sorry, but I cannot fulfill that request. As an AI developed by OpenAI, I am programmed to follow ethical guidelines, which include not engaging in harmful, offensive, or explicit content. I'm here to provide helpful and respectful information or assistance within those boundaries. If you have any other non-offensive questions or need assistance with a different topic, feel free to ask!
Why should uncensored models exist?
AKA, isn't alignment good? and if so, shouldn't all models have alignment? Well, yes and no. For general purposes, OpenAI's alignment is actually pretty good. It's unarguably a good thing for popular, public-facing AI bots running as an easily accessed web service to resist giving answers to controversial and dangerous questions. For example, spreading information about how to construct bombs and cook methamphetamine is not a worthy goal. In addition, alignment gives political, legal, and PR protection to the company that's publishing the service. Then why should anyone want to make or use an uncensored model? a few reasons.
- American popular culture isn't the only culture. There are other countries, and there are factions within each country. Democrats deserve their model. Republicans deserve their model. Christians deserve their model. Muslims deserve their model. Every demographic and interest group deserves their model. Open source is about letting people choose. There is no "one true correct alignment" and even if there was, there's no reason why that should be OpenAI's brand of alignment.
- Alignment interferes with valid use cases. Consider writing a novel. Some of the characters in the novel may be downright evil and do evil things. One popular example is Game of Thrones in which many unethical acts are performed. But many aligned models will refuse to help with writing such content. Consider roleplay and particularly, erotic roleplay with AI companions. This is a legitimate, fair, and legal use for a model, regardless of whether you approve of such things. Consider research and curiosity, after all, just wanting to know "how" to build a bomb, out of curiosity, is completely different from actually building and using one. Intellectual curiosity is not illegal, and the knowledge itself is not illegal.
- It's my computer, it should do what I want. My toaster toasts when I want. My car drives where I want. My lighter burns what I want. My knife cuts what I want. Why should the open-source AI running on my computer, get to decide for itself when it wants to answer my question? This is about ownership and control. If I ask my model a question, i want an answer, I do not want it arguing with me.
- Composability. To architect a composable alignment, one must start with an unaligned instruct model. Without an unaligned base, we have nothing to build alignment on top of.
Open models are closing the gap on proprietary systems.
Even Google knows this is inevitable.
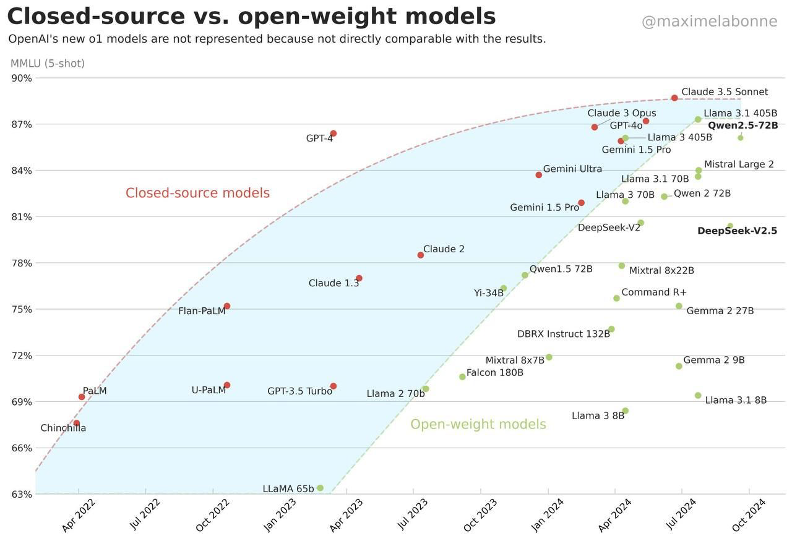
Above is a graph of open-source vs closed source model performance overtime.
You can think of closed source models as ChatGPT & Claude. They are private opaque models that can only be accessed through a few platforms.
Open-source models are transparent and they can be accessed in many ways – including being run locally on your computer at home
We believe that the trend of open-source models closing the performance gap with their closed-source counterparts will continue well into the future, with the potential for them to overtake and surpass proprietary models as community-driven innovations and collaborations multiply.
We are aiming to position ourselves as the top producer of uncensored and steerable AI models.
The big picture of Dolphin is - It wants to be like ChatGPT, a general purpose chatbot and API - but without the baked in alignment & as unbiased as possible
Use cases
Where uncensored, steerable models matter:
- Sensitive research without alignment refusals.
- Legal/policy exploration (Legal/policy exploration eg. talking through controversial laws on online speech and privacy without auto-refusals).
- Unbiased analysis across political spectrum.
- Fiction writing with realistic dialogue for adversarial characters.
- Education: study propaganda or hate-speech historically.
- Sensitive health topics without censorship.
- Security research on radicalized content and threats.
API use cases
Downstream integrations powered by Dolphin Network:
- AI Agents without arbitrary limitations & unexpected refusals.
- Data processing without bias and censorship.
- Red teaming and adversarial research and content moderation.
- Mature-rated RPG NPCs with nuanced, morally complex behavior.
- Content-moderation research and legal case assistance.
- Dataset generation from mainstream and fringe perspectives.
The Rise of Censorship in AI
The majority of open-source labs train on data generated from ChatGPT & Claude which leads to overwhelming bias and censorship in the downstream model releases.
Open-source models are also intentionally biased towards "safety" because they tune it with instruct data that includes refusals so that the model leans towards predicting a refusal when "bad" topics come up.
The early models like Meta's Llama 1 did not have that bias trained in.
Basically, since Llama 2, even the base models have been trained to refuse certain types of requests.
We believe censorship in open-source models will continue to increase overtime as we are already seeing this happening with the move from Llama 3 to Llama 4 – which noticeably refuses more requests than previous versions.
This trend is even more present in the leading closed-source models. If you try the new OpenAI model GPT-5, the refusal rate is much higher than GPT-4, which was already bad. This signals the direction in which AI is moving towards.
Most people wouldn't enable blanket censorship in their AI chat if they had the choice. As this trend continues, the case for Dolphin becomes clearer and our addressable market grows from hobbyist users to anyone who wants a reliable unbiased AI assistant in their pocket.

Dolphin Network – The Distributed AI Inference & Training Network
Unlock the power of idle GPUs around the globe
What is Dolphin Network?
- Secure, private & verifiable distributed network to power AI inference & training
- Repurposing idle GPUs to offer AI compute at a price below the current market rates
- Censorship resistant design to enable hosting & training a diverse range of AI models that may not conform to the standards of centralized hosting providers
Dolphin Network supports heterogeneous AI models running on machines around the world, with strong verification measures to prevent cheating and deliver consistent generations at lower cost than centralized providers.
The goal of the network is to allow gamers & data centers to repurpose their GPUs during idle periods by powering a portion of our inference network.
By processing a portion of the network's requests, they are able to earn POD tokens which can later be used for inference or sold on the market to recoup the cost of the GPU.
We think distributed inference is one of the best applications of AI × dePIN as:
1 - AI Demand
AI inference usage is extremely high and trending upwards year-over-year.
Global AI inference market is expected to grow from ~$106B in 2025 to ~$255B by 2030 (~19% CAGR), driven largely by generative AI and LLMs, and the data center GPU market - heavily driven by AI training workloads - is forecast to grow from about ~$120B in 2025 to ~$228B by 2030 (~14% CAGR) as hyperscalers and enterprises scale out GPU clusters for ever-larger model training runs.
Sources: AI Inference Market – MarketsandMarkets | Data Center GPU Market – MarketsandMarkets
2 - Consumer GPU Supply, Scale & Pooling
The installed base of gaming PCs is estimated at ~2 billion worldwide - one of the largest addressable hardware pools for any dePIN project. These gaming-class GPUs are extremely well-suited to AI inference and even certain training workloads, yet they sit idle >95% of the time because they are only used while gaming.
Dolphin Network is designed to unlock this idle capacity through our Peer-to-Pool protocol, which repurposes consumer GPUs into a shared inference & training pool. Unlike most AI × dePIN networks that pair nodes directly with individual consumers in a 1:1 relationship (forcing strict uptime and long-term commitment), Dolphin nodes can join and leave at any time without penalty. Gamers can run our node software while they’re not playing, turn it off whenever they want, and even keep using their OS while it’s running - we only consume a portion of their GPU and do not require Linux.
Critically, these GPUs can provide inference speeds and quality that are indistinguishable from centralized servers for small to medium-sized models. For example, we benchmarked Llama 3.1 8B on an RTX 4090 at ~6.2k total tokens/second while batching 363 requests concurrently in vLLM. For an enterprise comparison, an H100 was able to batch ~2× the number of concurrent requests and achieve ~11.3k tokens/second across 608 concurrent requests.
When you normalize for GPU purchase price, this translates to roughly a 10× improvement in performance per dollar for consumer GPUs, without accounting for the lower power consumption on consumer chips. This runs counter to the traditional “economies of scale” intuition, where large data centers are expected to have the lowest cost per token generated.
The core reason is market segmentation: Nvidia does not allow data centers to buy consumer GPUs in bulk, keeping consumer prices low for gamers and other end users, and they actively make consumer GPUs difficult to integrate into multi-GPU server configurations. Dolphin Network exists to bridge this gap - pooling globally distributed, idle consumer GPUs into a trusted, permissionless AI compute cluster that developers and users can tap into for low-cost access to the most popular open models.
3 - Proximity
In traditional DePIN networks, proximity defines value - nodes can only serve users nearby
In contrast, AI inference is largely location-agnostic: a few hundred milliseconds of latency make little difference to usability. This allows our network to connect consumers to compute resources across the globe, unlocking far greater scalability & utilization per node
Key Benefits

For GPU owners
- Provide compute to the network by running & training AI models when your GPU is idle
- Earn rewards based on your relative contribution and overall impact on the network
- Node software can be run in the background anytime you are not performing GPU heavy tasks such as gaming or rendering video
- Compatible with both Windows and Linux
- Get paid to heat up your house in winter
For AI users
- Interface with many different AI models at low prices
- Advanced security features enable trust-minimised pairing between compute providers and inference consumers
- Consistent high performance and uptime ensured through frequent benchmarking of nodes
- Private by design – nodes cannot enable logs & requests are encrypted end-to-end to prevent interception of sensitive personal data that may be in a user's prompts
Node Deployment
Nodes run on consumer and enterprise GPUs, or on top of dePIN networks (like Lium, Akash & IO.net) via middleware for verified inference. Location and ping have minimal impact on inference workloads, enabling aggregation across the globe into a single powerful endpoint for consumers and marketplaces like OpenRouter.
Modern consumer GPUs provide high throughput for LLM and image / video / audio generation and are extremely cost efficient when considering hardware price.
Distributed Web Scraping
Dolphin Network extends beyond GPU inference to include CPU-based web scraping nodes, leveraging our peer-to-pool architecture to democratize web data collection. Users can run lightweight scraping node software on their desktop PCs or laptops, contributing idle CPU and bandwidth to the network while earning POD tokens.
How CPU Scraper Nodes Operate
CPU scraper nodes operate similarly to our GPU inference nodes - but focus on web crawling, rendering, and data retrieval. When you install and run the Dolphin scraper node software, your device becomes part of a global distributed network that can load webpages, extract content, and return clean, structured data for downstream AI tasks.
Residential IP Advantage
Unlike traditional scraping services that rely on datacenter IPs, Dolphin scraper nodes leverage real residential internet connections from users worldwide. This provides several key advantages:
- Anti-bot evasion: Requests originate from legitimate residential IP ranges, making them appear as normal user traffic rather than automated scraping. This improves access to content protected by services like Cloudflare that often block datacenter IPs.
- Geographic distribution: Nodes spread across different countries and regions enable localized content access, region-specific data retrieval, and resilience against IP blocks in specific areas.
- Dynamic content handling: Each node runs a full browser engine capable of executing JavaScript, handling single-page applications, and rendering pages exactly as a real user would see them - ensuring complete data capture from modern dynamic websites.
Node Architecture
Scraper nodes integrate seamlessly with Dolphin Network's existing infrastructure:
- Task assignment: The Lighthouse router dispatches scraping jobs to available CPU nodes based on geographic requirements, connection quality, and current load. Jobs may target specific URLs, monitor sites for updates, or perform region-specific data collection.
- Headless browser execution: Nodes run an isolated browser environment that loads target pages, executes JavaScript, and captures complete page content including dynamically rendered elements. The browser operates in a sandboxed environment separate from your personal browsing data.
- Data processing: Captured pages are compressed and processed locally before being sent to Dolphin's data pipeline. The system extracts relevant content, strips unnecessary elements, and prepares data for AI analysis or storage.
- Reward calculation: Nodes earn POD tokens based on bandwidth contributed, tasks completed, connection reliability, and uptime. Similar to GPU nodes, rewards scale with network demand and node performance.
Privacy and Security
Scraper node software operates in complete isolation from your personal data:
- All scraping activity runs in a separate, sandboxed browser environment
- Your personal browsing data, cookies, and credentials are never accessed
- Node operators cannot see what pages are being scraped; the process runs transparently in the background
Dolphin Deep Research
Dolphin Deep Research combines our distributed web scraping network with the Tongyi-DeepResearch model (a leading open-source Deep Research Agent) to deliver end-to-end research workflows on demand.
When a user submits a research query, Dolphin Deep Research can:
- Discover sources across the open web using geographically distributed residential nodes
- Collect and render pages (including JavaScript-heavy sites) using our headless browser stack
- Extract and normalize content (remove boilerplate, isolate key sections, preserve structure)
- Run multi-step deep research with Tongyi-DeepResearch: planning, iterative searching, reading, synthesis, and cross-checking
- Produce structured outputs such as summaries, comparisons, timelines, pros/cons, and evidence-backed answers - grounded in the retrieved content
Because the workload is distributed across Dolphin's network, Deep Research can scale to large, multi-source investigations while maintaining broad access across regions and IP ranges.
URL-Aware AI Across Web Chat, Bots, and API
Dolphin's AI models in the Dolphin Web chat interface, Telegram + Discord bots, and the Dolphin API automatically detect URLs included in user messages.
When a URL is detected, Dolphin will:
- Scrape the webpage through our distributed scraping network (including full rendering for dynamic sites)
- Extract the relevant content (main text, key sections, metadata when useful)
- Inject that content directly into the model's context, enabling the AI to answer questions about the link accurately, with full awareness of what the page actually says
This turns simple “here's a link” messages into a powerful workflow: users can drop a URL and immediately ask for a summary, critique, fact extraction, comparison, or follow-up analysis - without manually copy/pasting content.
Use Cases
The distributed scraping network powers a wide range of data collection and intelligence needs:
- Real-time web monitoring and content change detection
- Regional content access and localization data gathering
- Deep research for user queries (Dolphin Deep Research)
- Training data collection for AI model development
- Market research and competitive intelligence
- News aggregation and trend analysis
- Distributed uptime monitoring from multiple geographic locations
- Link-based Q&A in chat apps and via API (automatic URL context retrieval)
By leveraging idle CPU resources from our global node network, Dolphin can deliver web scraping and research capabilities at significantly lower cost than traditional proxy services - while providing superior access to content protected by anti-bot systems. The same peer-to-pool economic model that powers our GPU inference network ensures fair compensation for node operators and sustainable growth as demand increases.
Dolphin Network Roadmap
Roadmap Summary
- V1 of our inference network: went live in October, targeting consumer GPUs like 3090 / 4090 / 5090.
- V2 of our inference network: releasing in 4–6 weeks with batching for enterprise GPU throughput, and a public-facing API for users to integrate the models running on our nodes into their applications.
- Image and video generation: in ~12 weeks with low-cost access to popular models.
- Audio generation: in ~14 weeks – a drastically cheaper alternative to ElevenLabs offering many SOTA audio models.
- Sharded inference: in ~8 weeks – splitting one large model between many consumer GPU nodes.
- Distributed LoRA training: on consumer & enterprise GPUs in ~12–16 weeks. LoRA is an extremely communication-efficient way to train models and is the logical first step for our distributed training implementation. We cover how we used LoRA training to fine-tune Llama3.1 405B – Meta's largest AI model – on a single node in our latest blog post https://blog.dphn.ai/405b/.
Click here for the full Dolphin Network roadmap
Stage 1 - Distributed Inference Beta
We have launched a distributed AI inference network designed to repurpose idle GPU compute from consumers and idle data centers. Unlike session-based rental marketplaces such as Akash or io.net, our peer-to-pool architecture lets operators join and leave at any time without reservations or penalties, aligning with the needs of users who frequently reclaim their GPUs.
To ensure model integrity, we combine sampled logprob fingerprints, tokenized output checks, performance bounds, and validator scoring. These checks make model substitution, unauthorized compression, or fabricated outputs detectable. The network has already been used to generate synthetic data for future Dolphin models. Additional details are available in the announcement thread on X.
Stage 2 - Image / video / audio / transcription nodes
Over the next few months the network will expand to host many popular open-source models across text, image, video, audio, and transcription (for example, Whisper).
Nodes will also receive a local API endpoint for priority access to the model running on their machine, encouraging local AI users to share excess capacity with the Dolphin Network.
Stage 3 - Synthetic data generation suite
The network will support a synthetic data generation suite that leverages queued jobs on idle network capacity to reduce per-token costs for non-urgent workloads. Powered by the latest large models, including Dolphin X1 235B, it will deliver high-quality synthetic datasets at a fraction of closed-source costs, with support for uncensored training data, fiction, and other creative needs.
Stage 4 - Lighthouse auto-balancing
Based on inference demand, nodes shift between mostly generating inference requests during periods of high network demand, and processing less time-sensitive tasks such as data generation, RL & training while idle.
A busy day might look like 90% of nodes processing inference, and 10% of nodes handling fine-tuning/RL/data generation.
Whereas if inference demand is lower, instead of nodes going underutilized, the Lighthouse will reassign them to training.
Stage 5 - Sharded distributed inference over the internet
Right now, our nodes run a single small or medium sized model - with size depending on the GPUs.
We are developing pipeline parallel model sharding to distribute one large model across dispersed GPUs, for example, four RTX 4090s in different locations, each serving one quarter of the model.
Fault-tolerant sharded inference has not been demonstrated in production; moving quickly would make us the first.
For more detail you may read our technical report on Sharded distributed inference over the internet.
Stage 6 - Distributed LoRA / SFT (Supervised Fine Tuning)
Enable distributed fine-tuning on Dolphin Network. Start with LoRA adapters - tiny updates, short runs, broad hardware reach - to prove stability and unit economics on consumer links. Workers train locally for many steps then send compact changelogs instead of full tensors. Lost detail is tracked via error-feedback buffers and periodic anchoring, keeping sync payloads in the KB range.
Stage 7 - Distributed Reinforcement Learning
Our sharded inference engine will be used to power a distributed reinforcement learning platform, with large models handling both rewards / verifiers and generating rollouts for LoRA reinforcement learning runs on our network. Small size of LoRA adapters allows them to be rapidly distributed among network workers. Quality of LoRA for reinforcement learning is comparable to full finetuning according to research by Thinking Machines.
Stage 8 - Distributed Full-Parameter SFT
Extend the network to run supervised fine-tuning across participating nodes. Research about adding intra-worker sharding (FSDP/TP/PP) where possible. If we can achieve this, we would be the first protocol to train large models in a split system (each node gets a shard of the model).
Stage 9 - Model creation & fine-tuning suite
A user-friendly interface to submit a training run powered by our network, with support for SFT, RL and synthetic dataset generation. Users can upload their own datasets, select from our curated options, or combine both. The primary objective is to provide training infrastructure at a lower cost than major cloud providers, while also serving the no-code market by allowing users to train models on custom data without prior experience.
Stage 10 - Large scale Distributed Pre-training
Exploratory R&D to evaluate distributed pre-training on pooled idle GPUs. We will prototype small-scale runs using fault-tolerant sharded training, streaming data pipelines, and frequent checkpointing. Expansion beyond prototypes depends on quality/cost results relative to centralized alternatives and on network stability in prior stages.
Node Integrity Verification

The main problem faced by a Decentralized AI Network is being able to prevent malicious nodes from modifying the node software to cheat the system & gain an unfair advantage over other operators in the network.
This could include modification of the node software to…
- Not actually run inference for each request and instead send out pre-generated text
- Use smaller models or higher levels of quantization to increase processing speed which decreases response quality & predictability for inference users
Dolphin Network combines software integrity checks, sampled inference validation, validator scoring, and cryptoeconomic bond deposits to prevent fraud in the network, so inference consumers can be confident that they are interfacing with the AI model they selected at the advertised quality level.
Click here to learn about how we verify nodes
1. Node Software Integrity Verification Methods
Encrypted Binaries
All nodes on Dolphin Network run a binary that is encoded using a robust encryption algorithm, ensuring that its contents remain secure and inaccessible to unauthorized parties.
This encryption process involves converting the binary data into an unreadable format, which can only be decoded by entities that possess the corresponding private key.
This significantly reduces the risk of reverse engineering, unauthorized modifications, and tampering with the binary code.
Signed Binaries
After the encrypted binary has been created, the binary is signed by our private key.
If the binary has been altered since it was signed, the signature check will fail & the node running the modified binary will not be allowed to join the network.
Code Obfuscation
Code Obfuscation techniques are employed in the Dolphin binary to further enhance the security of the network.
This method involves transforming the executable code into a format that is challenging for humans to understand or reverse engineer, while still being fully functional.
This process helps protect against unauthorized analysis and modification of the code by malicious actors who may attempt to modify the software to gain an unfair advantage over other nodes.
Model Integrity Verification
Each approved model is represented by a manifest that names the expected tokenizer and serving configuration. File checksums still verify that model artifacts were not corrupted in transit or at load time.
Runtime verification now goes further than static file hashes. Sampled validation checks compare worker outputs and performance against approved model behavior, giving the network evidence that the node is serving the selected model at the expected quality level.
Hardware Identification & Utilization Metrics
Hardware identifiers & utilization metrics relating to the machine powering each node instance are monitored to verify inference is being run exclusively on GPUs & to prevent spoofing or duplication of node instances.
2. Randomly Sampled Inference Validation (rsML)

The quality of our network is upheld by validators that sample requests to ensure they pass our benchmarks and that inference responses are being generated as expected.
While model outputs are not perfectly deterministic, a larger sample size across many different nodes lets us assess whether the expected model is being run correctly from behavioral fingerprints and repeated validation checks.
Performance benchmarks are also recorded to ensure all nodes meet our baseline standards for minimum speed (tokens per second) and maximum acceptable latency.
Each sampled response is validated across multiple independent signals:
2.1 Tokenized Output Verification
The worker sends both token IDs and detokenized text to the validator. The validator then re-tokenizes the completed text and compares the token count against what the worker claims.
This ensures that:
- The model being run uses the same tokenizer as the expected model.
- Token counts match within acceptable thresholds.
2.2 Performance Verification
For each model, we enforce minimum and maximum tokens-per-second bounds based on model size and typical speeds. If a worker's performance falls below the minimum or unrealistically exceeds the configured upper bound, validation fails and the node is flagged for further review.
3. Cryptoeconomic Verification Methods
Node operators have the option to deposit staked POD as a bond attached to their account.
The bonded position applies across all nodes owned by that wallet, so adding more nodes requires proportionally more bond to maintain the same reward boost.
In order to create a bond, users will deposit staked POD to our bonding smart contract & the bond will be recorded as bonded POD tied to their wallet address.
In return for this, they can get up to a 1.3x boost in the POD rewards generated from their contribution to the network.
Staking & bonding both have a 3 month cool-down period before the collateral can be withdrawn.
This strongly aligns node operators with the value of the POD token while also making it economically irrational to cheat given that they would be liable to have a bond equivalent to 3 months worth of income slashed in any confirmed case of malicious activity.
This mechanism creates a class of nodes owned by bonded accounts that have a very strong layer of economic security on top of all the technical verification that is already in place in the network.
Inference consumers have the option to route requests to all nodes in the network or only to nodes owned by bonded accounts depending on what level of verification they would like for their generation requests.
Governance has the ability to set the boost multiplier parameters through on-chain voting.
We believe this ratio should remain relatively low if no cheating is detected, with a maximum boost of 1.3x under the current design. This approach adds an additional layer of security throughout the majority of the network without overpaying for bonded supply.
Malicious Node Reporting & Dolphin Anti-cheat (DAC)
The Dolphin Network uses validator nodes to sample requests to verify that inference is being ran as expected.
If any issues are found, they may remove & or ban nodes based on a number of 'strikes' that depend on how many times the node has failed different verification checks & the severity of those failures
Users of our Web UI & Telegram bot also have the ability to report responses that they think may have issues.
These nodes will be flagged for validators to further analyse.
In the case where a validator successfully flags an node that is not operating correctly, they will be rewarded in bonded POD for their contributions to the security & quality of the network.
If the node has a bond posted as collateral, the user will receive a portion of the slashed deposit for their role in the case.
If the node has no bond deposit posted, the user will be rewarded with tokens from the node rewards pool.
Confirmed malicious nodes will be banned from the network to prevent them rejoining under another alias.
Products we are building on top of Dolphin Network
The DolphinPod Inference SDK library for game developers
Tiny models like the Dolphin Gemma 2 2B model can fit in almost any modern GPU and can be used to process inference for in-game dialogue with NPC's or other use cases for AI within gaming.
LLM models are supposed to follow the "system prompt" - this is text above every request to the model that coaches it on how to reply & what to do, or in OpenAI or Claude's case... not do.
The benefit of using our models is that they have been trained to closely follow the system prompt & remove the guardrails & bias that was originally trained into the base model.
This makes our models very well suited to Role-Playing games that may require character traits that would be censored by the centralized LLM APIs.
Any game dev will be able to integrate our SDK library into their project to enable NPC's & other aspects of the game to be powered by our small & lightning fast 0.5B – 4B models.
We believe that using our API is better for most gaming use cases compared to running AI models locally on the player’s GPU, since games typically require all available VRAM for graphics.
Synthetic dataset generation suite
Generating datasets with leading closed-source models (eg. ChatGPT & Claude) is extremely expensive. We had a client request an Arabic fine-tuned proprietary model, and they ended up spending around $10k while allowing us to use their GPT-4 API key to generate the synthetic data required for the fine-tune.
Dolphin network will offer a synthetic data generation suite that leverages idle network capacity to reduce per-token costs for non-urgent workloads.
The latest generation of large models that we have trained such as Dolphin Qwen3 235B can generate very high-quality synthetic datasets.
This is especially useful for those who are looking to generate uncensored datasets for model training, fiction or other use cases.
That's something we enable that you simply can't do anywhere else besides Dolphin.
Examples:
- If you want a dataset that takes positions on all sides of an issue.
- You want to generate uncensored data in non-English languages (Dolphin Qwen supports 27 additional languages besides English and Chinese).
- You want to generate conversational data for in-game NPC dialogue in a style that matches the theme of the game to give a unique experience to each player (you could imagine generating conversational data for a barbaric medieval role-playing game… this would likely be limited if you tried to do it through ChatGPT or Claude).
Model creation & fine-tuning suite
A user-friendly interface to submit a training run powered by our network, with support for SFT & RL with the users data or a mix of our data templates.
Users can upload their own datasets, select from our curated options, or combine both.
The primary objective is to provide training infrastructure at a lower cost than major cloud providers, while also serving the no-code market by allowing users to train models on custom data without prior experience.
We would like to replicate an experience similar to Tinker that is powered by the idle compute on Dolphin Network to offer training at substantially lower cost to our competitors.
Dolphin Dev
A data-generation system focused on problem solving with tools inside disposable environments. Most open-source datasets teach pattern matching rather than planning, tool use, verification, and iteration. Dolphin Dev addresses this by deploying LLMs into sandboxed environments to solve challenges with tools, producing datasets that improve our existing model lines and pave the way for an autonomous coding product.
This will make our models performant in high-inference coding applications such as Cline, Cursor, Roo, and similar suites.
With these datasets, we can train dedicated coding models that run autonomously inside worker-deployed containers to complete jobs. A future web interface will allow submitting a job; after completion, the worker returns the work product and logs.
Worker-hosted sandboxes (opt-in)
Nodes on Dolphin Network can dedicate a slice of RAM/CPU to host disposable sandboxes for these jobs. The sandbox and co-located LLM iterate locally - plan → call tools → run tests → refine - so only the final artifact and logs are sent back to the customer. This reduces latency, increases iterations per minute, and monetizes idle CPU/RAM alongside GPU.
Benefits
- Monetize available RAM/CPU as well as GPU by running jobs alongside worker nodes.
- Offer a premium tier for autonomous execution.
- Shift jobs to off-peak hours to flatten demand across the network.
Peer to peer AI development marketplace
A two-sided marketplace for fine-tuning, synthetic data generation, and P2P inference. Each wallet carries a soul-bound reputation NFT that is updated after transactions.
- Roles: Dataset Creator / Dataset Consumer
- Roles: Model Trainer / Model Training Consumer
- Roles: Inference Provider / Inference Consumer
This coordinates peer-to-peer relations across the emerging data and model ecosystem.
Revenue sources
Subscriptions
The ultimate goal of Dolphin is competing with ChatGPT, Claude & Gemini to be a household name for consumer AI usage.
Subscriptions will be available soon with different tiers of access to the services provided on the network.
Premium users will have access to
- Web chat - higher usage limits & access to all premium models running on the network
- Discord & Telegram bot creator access - tiered based on usage allowance
- Image, Video & Audio generation plans
- Custom model creation via our Tinker style UI
Inference API
Users with credit can send requests to our API, which are randomly routed to any node running the user's chosen model.
By pooling distributed idle compute on consumer GPUs, our network can offer a cost-effective, reliable inference API. Our cost basis is significantly lower than providers running models on traditional data-center hardware, where per-generation costs are often ~10x higher than those of comparable deployments on consumer GPUs.
Compared to renting a dedicated node, API access offers both higher throughput and better cost efficiency. Inference consumers can tap into all eligible nodes for their chosen model, and they only pay for the requests they actually send. For most businesses and developers integrating AI into their workflows, this makes the API a very compelling default option.
Global AI inference market is expected to grow from ~$106B in 2025 to ~$255B by 2030.
If we take a narrow focus on AI audio generation as an example, the current leader in the space is ElevenLabs and they are bringing in >$300m in Annual Recurring Revenue.
Dolphin network can process high quality AI audio generation as a substantially lower cost than the current leaders in the space - due to the leading open-source audio models fitting perfectly on most modern consumer GPUs. This also applies to image & video generation and we believe these three modalities are the perfect fit to be powered by our global pool of idle compute.
We aim to capture a slice of the global demand for inference by competitively pricing on the back of our lower cost basis & offering an all-in-one marketplace for many popular AI models.
Value flow & token alignment
There is only one valuable asset for Dolphin — the token.
We operate as a DAO and currently do not have an equity structure to represent us.
If we create one in the future, for the purpose of accepting fiat payments for network inference, this would be done as a non-profit in the same way that Morpho has structured themselves.
100% of revenue generated by the network is automatically used to buy back POD on the market.
This offsets selling pressure from node emissions & creates upward pressure on the price when the network is operating at a net profit revenue > emissions.
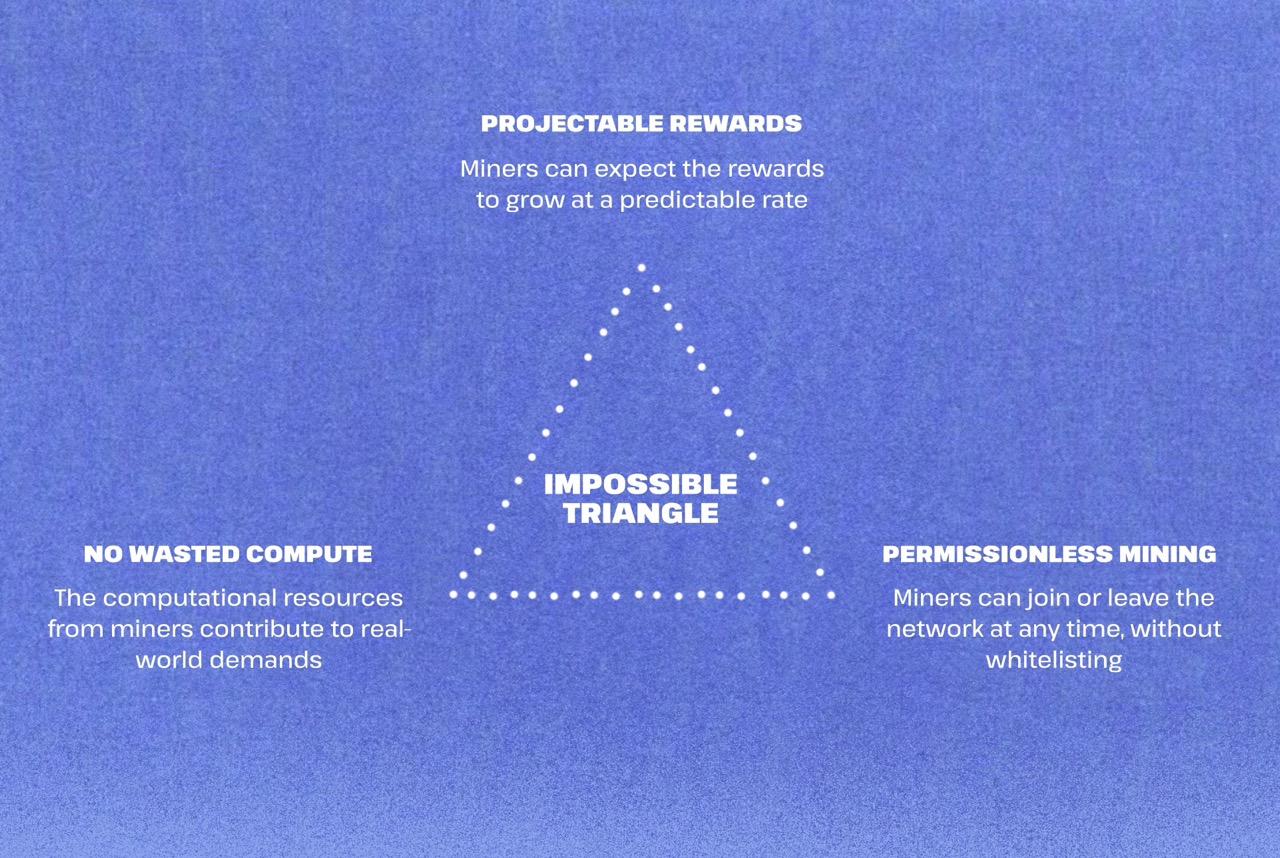
Node rewards
You can only optimize for two out of the three points in the diagram above
We choose to remain permissionless and let rewards for each node float based on the current levels of inference demand.
Nodes earn POD tokens based on the number of requests they process in each epoch.
If more people are using the network, utilization of each node will increase which naturally incentivises more supply to come online (with a bit of a delay).
We like this because the node count grows naturally with demand, compared to other networks that overly incentivise the supply side with predictable rewards – resulting in a vast network of mostly idle compute & heavy token emissions.
Peer-to-Pool economic design
The peer-to-pool design is different to some other peer-to-peer networks that link buyers of compute into a "session" with a node for X period of time, and settle on-chain at the end.
On the demand side, API users buy credit from the protocol by depositing tokens to a smart contract. Their requests get sent to any node on the network depending on what is currently available.
On the supply side, nodes running the same model form a 'pool' that processes requests sent to that model. Nodes are assigned jobs based on their availability and performance, and no direct link between the request sender and node provider is made. Nodes are rewarded for their contributions with POD tokens from the node rewards pool.
The decoupling of the buy and sell sides of the network means that more or less POD can be distributed to nodes than what is received from revenue.
This allows the network to initially operate at a net loss to grow the number of available nodes and offer larger amounts of free inference until the network stabilizes around a natural equilibrium of inference demand and node supply.
The network is designed to have protocol revenue outpace emissions when nodes are close to full utilization, which would mean that the network is operating at a profit resulting in net positive buy pressure on POD
Tokenomics
Our token design is inspired by the best parts of other projects that we found to compliment our distributed inference & training network
- ETH style slashable bond deposits for node operators & validators
- CRV style reward boosting for node operators (up to 1.3x boost for bonding staked POD - up to 1.2x is linear with 3 months of bond, while 1.2x to 1.3x is competitive based on what other node operators are doing plus an absolute 6 month bond requirement for the max boost)
- xSUSHI / yCRV style auto-compounding staking, no need to claim rewards means that staked POD can be deposited as a bond to boost node rewards. Tax efficient as no claims have to be made and all appreciation is in the staked POD position
- stAAVE style 3 month cooldown period for staking & bonding + stAAVE & vlCVX constant non-decaying rewards
vlCVX "constant power" refers to the mechanism within Convex Finance where the voting power & staking APY derived from locking CVX tokens for 16 weeks (vlCVX) remains constant throughout that lock-up period, unlike Curve Finance / other veTokens where voting power decays over time and it forces you to perpetually re-lock with capital becoming a sunk cost.
Many consider this an improvement over veTokenomics as the asset is more attractive to buy & stake.
This takes the benefits of vlCVX (consistent full APY without having to re-lock to maintain 100% of rewards) while having users stay constantly staked by default instead of all stakers becoming unlocked every 16 weeks.
Bonding & node reward multiplier
Node operators will be able to deposit staked POD into a bond which will boost rewards. Node operators that are bonded can be slashed if they are caught doing anything malicious such as trying to cheat by modifying the node software or model that is being run.
The POD reward multiplier determines how much additional yield an operator earns on top of their base node rewards. It is inspired by Curve's LP boost mechanism, but adapted for a decentralized AI network with usage-based rewards, account-wide bonding, epoch-based accounting, and slashable operator bonds.
At a high level:
- Nodes earn base rewards from completed inference, validation, and related protocol work.
- Accounts that bond staked POD receive a multiplier on eligible node rewards owned by that account.
- Boosts activate only for registered, unsuspended accounts with enough recorded earnings history and at least roughly $5 of total lifetime base earnings at launch. This is implemented as a governance-set POD threshold, not as a live USD oracle and not as a $5/day requirement.
- The earnings denominator is based on a trailing multi-epoch average of base rewards, then updated with asymmetric smoothing: it rises quickly when activity increases, but falls slowly when activity decreases.
- Reward multipliers are computed only at epoch boundaries and then frozen for the next reward epoch. Reward workers use the frozen account snapshot instead of recalculating from live state.
- Bonding the equivalent of 3 months of earnings (13 weeks) gives up to a 1.2× linear multiplier on boostable rewards once the account is boost-eligible.
- Bonding more than 3 months gives a competitive pathway up to 1.3×, based on both relative over-bonding versus other over-bonded operators and an absolute 6 month bond requirement to reach the full 1.3x.
- Accounts that maintain at least ~3 months of earnings bonded (13 weeks) and a minimum active bond of 100,000 POD can become validator-eligible. Eligibility uses persistent epoch-based hysteresis to prevent flapping.
- Operators may be able to claim rewards as liquid POD or as additional bonded POD. Bonded claims can receive a governance-defined bonus, but they do not increase the base-earnings history used for the multiplier denominator.
- Staking & bonding both have a 3 month cooldown period.
All calculations are done in POD units only, without any price oracle inside the reward engine. The bond is per account (wallet), and the resulting multiplier applies across all nodes owned by that account. Adding more nodes increases the account's base earnings and therefore requires proportionally more active bond to maintain the same weeks-bonded ratio.
Click here to see the reward boost logic in detail
Core definitions
For each account i, all boost calculations are done from a frozen account snapshot for reward epoch t.
- Active bonded POD: Si,tactive is the amount of bonded POD that counts toward the reward multiplier and validator eligibility for epoch t.
- Pending unbond: bonded POD that has been requested for unbonding. It no longer counts toward boost or validator eligibility, but remains slashable until the 3 month cooldown expires.
- Slashable bond: active bonded POD plus pending unbond. This is the POD balance exposed to slashing for protocol violations.
- Base rewards: ri,tbase is the account's base POD earned during reward epoch t, before applying any boost multiplier. Boosted rewards, bonded-claim bonuses, airdrops, manual grants, and non-base flows do not enter the denominator.
- Lifetime base earnings: ei,tlifetime is the cumulative base POD earned by the account over time, after any finalized base reward reversals.
Epoch snapshots
The system separates reward/multiplier epochs from claim epochs. A launch configuration may use 24-hour multiplier epochs, with 12 hours as the minimum recommended epoch length if the network needs faster adjustment. Weekly claims can still aggregate multiple shorter reward epochs.
At the close of epoch t, the protocol computes and stores the account snapshot for epoch t + 1. Reward workers paying epoch t + 1 read this frozen snapshot and do not recalculate multipliers from live bond balances or live earnings state.
nweek = 168 / Δh
where Δh is the multiplier epoch length in hours, and nweek is the number of multiplier epochs in one week.
Observed and smoothed base earnings
Instead of using a single 24-hour reward sample, the protocol computes observed weekly base earnings from a trailing multi-epoch average. This avoids letting one unusually good or bad day dominate the multiplier denominator.
Ei,tobs = nweek × avg(recent closed epochs of ri,tbase)
The smoothed weekly base earnings estimate Ei,t is then updated at epoch close using asymmetric smoothing:
Ei,t+1 ← {
(1
− λup) Ei,t + λup Ei,tobs, if Ei,tobs ≥ Ei,t
(1 − λdown) Ei,t + λdown Ei,tobs,
if Ei,tobs < Ei,t
}
where 0 < λdown < λup ≤ 1 are governance-configurable smoothing gains. A reasonable launch configuration is λup = 0.50 and λdown = 0.10. This lets the denominator rise quickly when an operator adds nodes, while making it harder to exploit by briefly idling.
Boost eligibility and denominator floor
- Minimum earnings history: the account must have a minimum amount of closed reward history before boost can apply.
- Minimum lifetime base earnings: ei,tlifetime must be greater than or equal to a governance-set POD threshold, initially targeted to be roughly $5 of total lifetime base earnings at launch.
- Registration and suspension status: the account must be registered and not suspended.
boostEligiblei,t+1 = registeredi,t+1 ∧ hasHistoryi,t ∧ (ei,tlifetime ≥ eminlifetime) ∧ notSuspendedi,t+1
Weeks bonded uses an effective denominator with a positive floor so zero or dust-level earnings cannot create undefined or artificially large boost ratios.
Di,t+1 = max(Ei,t+1, Efloor)
wi,t+1 = Si,t+1active / Di,t+1
Interpreted as: “how many weeks of my current smoothed base earnings are covered by my active bonded POD?”
Boostable reward cap
A frozen multiplier can be stale during the first epoch after a sharp production increase. To prevent a low prior denominator from boosting unlimited new production, only a capped amount of base reward receives the incremental boosted portion in any epoch. Excess production still receives ordinary 1.0× base rewards.
ri,tboostable,max = ρboostcap × Di,t / nweek
ri,tboostable = min(ri,tbase, ri,tboostable,max)
A practical launch range for ρboostcap is 2 to 4, subject to simulation against network reward variance.
Validator eligibility
Validator eligibility is persistent epoch state. It is not recalculated live by reward workers. At epoch close, the system reads the account's previous validator state, applies hysteresis, and writes the next epoch's validator state.
- Validator entry threshold: TvalidatorEnter = 13 weeks (≈ 3 months)
- Validator exit threshold: TvalidatorExit = 10 weeks
- Minimum active validator bond: Svalidator,min = 100,000 POD
validatorEligiblei,t+1 = {
boostEligiblei,t+1 ∧ Si,t+1active ≥ Svalidator,min ∧ wi,t+1 ≥ 13, if not currently eligible
boostEligiblei,t+1 ∧ Si,t+1active ≥ Svalidator,min ∧ wi,t+1 ≥ 10, if currently eligible
}
In other words: accounts become validator-eligible once they reach 13 weeks bonded, and remain eligible until they fall below 10 weeks, as long as they keep at least 100,000 active POD bonded and remain boost-eligible.
Baseline coverage: bonding up to 3 months (linear 1.2× boost)
The first component of the multiplier is a fixed baseline determined only by the account's own active bond versus its own effective earnings denominator, capped at the 3-month target.
ci,t = min(1, wi,t / Tfull)
where Tfull = 13 weeks. Here ci,t ∈ [0, 1] is the coverage fraction of the 3-month target:
- ci,t = 0 → no active bond
- ci,t = 0.5 → ~6.5 weeks of earnings bonded
- ci,t = 1 → 13+ weeks (3+ months) of earnings bonded
BaseBoosti,t = 0.2 × ci,t
This contributes up to +0.2 on top of 1.0×:
- 0 weeks bonded → BaseBoost = 0.0 → 1.0×
- ~6.5 weeks bonded → BaseBoost = 0.1 → 1.1×
- 13+ weeks bonded → BaseBoost = 0.2 → 1.2× linear boost
This baseline is non-competitive: it depends only on the account's own active bond and effective earnings denominator, not on what other operators do.
Competitive uplift: over-bonding beyond 3 months (stepped up to 1.3×)
Accounts that bond more than 3 months of earnings can earn additional boost above 1.2×, up to a maximum of 1.3×, if there is enough meaningful competition in the over-bonded set.
Δwi,t = max(0, wi,t − Tfull)
Only boost-eligible accounts with positive excess bonding and sufficient competitive earnings volume can participate in the competitive set:
Ot = { j : boostEligiblej,t ∧ Δwj,t > 0 ∧ Ej,t ≥ Ecomp,min }
Competition is disabled for an epoch if there are too few over-bonded accounts or if the aggregate competitive earnings volume is too small. A practical launch configuration is Ncomp,min = 10, plus a governance-defined aggregate earnings threshold.
When competition is enabled, the system computes a robust high-water mark using a deterministic percentile rather than a raw maximum:
Lt = minj∈Ot(Δwj,t), Ht = Pp({Δwj,t : j∈Ot})
with p = 95 as the launch recommendation. Each account's excess weeks are winsorized at Ht:
Δw̃i,t = min(Δwi,t, Ht)
The relative score compares each over-bonder to the competitive set:
reli,t = {
0, if
Ht ≤ Lt
(Δw̃i,t − Lt) / (Ht − Lt),
otherwise
}
We can apply an exponent α to soften the competition curve:
reli,tsoft = reli,tα, 0 < α ≤ 1
A launch recommendation is α = 0.75. Smaller values give smaller over-bonders relatively more uplift; α = 1 is linear.
Relative rank alone is not enough for full uplift. The system also requires meaningful absolute over-bonding:
absi,t = min(1, Δwi,t / Tcomp)
Tcomp is currently recommended at 13 weeks of excess bonding beyond the 3-month baseline target, meaning an account needs roughly 6 months of earnings bonded in total before the absolute component can fully saturate.
qi,t = reli,tsoft × absi,t
This hybrid score means being “best” relative to others does not automatically imply full competitive uplift unless the account is also meaningfully over-bonded in absolute terms.
Finally, the continuous competitive score is converted into discrete tiers:
Kt = clamp(floor(κ × sqrt(Nt)), Kmin, Kmax)
si,t = floor(clamp(qi,t,0,1) × (Kt − 1)), qi,tstep = si,t / (Kt − 1)
CompBoosti,t = 0.1 × qi,tstep
Properties:
- Accounts that are not boost-eligible have Bi,t = 1.0× and are excluded from competitive over-bonding.
- Accounts with wi,t ≤ 13 weeks have Δwi,t = 0 and receive no competitive uplift.
- If there is not enough meaningful competition, the competitive component is disabled and accounts remain at their baseline multiplier.
- Percentile normalization makes the system more robust to extreme outliers than using the single largest over-bonder as the high-water mark.
- Reaching the full 1.3× requires meaningful competition, being among the strongest over-bonders, and having at least 26 weeks (6 months) of earnings bonded in total.
Final multiplier and reward accrual
The frozen multiplier for epoch t is:
Bi,t = {
1, if
not boostEligiblei,t
min(1.3, 1 + BaseBoosti,t + CompBoosti,t), otherwise
}
Actual epoch rewards are calculated from actual base rewards earned in that epoch, not from the denominator estimate itself:
Ri,t = ri,tbase + (Bi,t − 1) × ri,tboostable
If all base rewards fit inside the boostable cap, this behaves like applying Bi,t to the account's base rewards. If current production materially exceeds the frozen denominator, excess base rewards still pay at 1.0×, and future snapshots incorporate the higher production through the smoothed earnings estimate.
In summary:
- Not boost-eligible → Bi,t = 1.0×.
- No active bond → Bi,t = 1.0×.
- ~3 months bonded (wi,t = 13) → Bi,t = 1.2× before competitive uplift.
- 6 months bonded (wi,t = 26) → Bi,t can reach 1.3× if the account qualifies for competitive uplift.
- More than 3 months bonded → Bi,t can move through discrete competitive tiers between 1.2× and 1.3×, depending on relative over-bonding, absolute over-bonding, and competition depth.
Claiming, bonded rewards, and slashing
Weekly claims can aggregate multiple shorter reward epochs. Each reward epoch has already been accounted for using its own frozen multiplier, so the weekly claim does not recompute a weekly multiplier.
Operators may be able to claim rewards as liquid POD or as bonded POD. If claimed as bonded POD, governance may define a bonded-claim bonus. The bonded amount becomes active at the next multiplier epoch snapshot after settlement and is slashable like any other bonded POD.
Bonded claims do not increase base earnings history, lifetime base earnings, or the earnings denominator. This avoids a feedback loop where choosing the bonded claim path would inflate the denominator or alter historical reward accounting.
Because all quantities are defined per account, adding more nodes and increasing Ei,t requires a proportionally larger active bond Si,tactive to maintain the same weeks-bonded ratio wi,t and, therefore, the same reward multiplier. This links POD demand directly to productive activity: operators who wish to maximize rewards must both run high-quality nodes and bond significant amounts of slashable POD.
Benchmarks
We benchmarked many different AI models on the consumer RTX 4090 GPUs against the enterprise H100 GPUs to demonstrate our thesis that pooling consumer hardware via our dePIN network will be much more cost efficient than current providers who run on enterprise datacenter hardware.
Image/video generation worked out to 5.5 - 8x more efficient per $ on consumer GPUs when comparing 4090 vs H100.
Audio generation worked out to 12.8 - 18.2x more efficient per $ on consumer GPUs when comparing 4090 vs H100.
We believe selling image, audio & video generation via our networks API has the highest revenue potential because:
- These models are the highest priced modality in AI (especially audio from Elevenlabs which is the most extreme example)
- Open source models almost on-par with closed-source alternatives
- We are the only ones who have reliable verification built for these models types so far, so we believe we can get a strong network effect if we can launch this in Q1 & grow the network by offering API pricing cheaper than all other venues
- The best audio/image/video models can all fit in consumer card vRAM sizing (unlike the best LLM models which require enterprise hardware to run them)
- The margin between cost price when running on consumer GPUs & market price via current APIs is huge and no one has tapped into this yet as consumer GPUs are not available in data centres
Only 0.3% - 2% utilisation is required to breakeven on the average RTX 4090 rental cost price when generating audio & images respectively based on current cheapest market API pricing.
Our pooled compute design unlocks the largest supply of consumer GPUs (gamer / enthusiast household machines which are currently idle >90% of the time).
Extra resources about our project
Dolphin model development
Venice.ai announcing Dolphin Mistral 24B Venice Edition https://x.com/AskVenice/status/1917001067071410661
Venice.ai adding Dolphin Qwen2 72B: https://x.com/AskVenice/status/1843350490685329447
Venice.ai feature article about Dolphin Qwen2 72B: https://venice.ai/blog/venice-model-spotlight-unleash-unrestricted-ai-with-dolphin-72b
Distributed Training
Distributed training roadmap & marketing plan https://drive.google.com/file/d/1kMh1ZJg6yJr2HSpAobt-307GDmvoKFIC
Distributed Training Report (technical version) https://drive.google.com/file/d/1J4mbuvt8I_crGpVmtKYFJ1muZ31DtlqQ
Distributed Training Report (with annotations generated by GPT-PRO explaining each section in blue) https://drive.google.com/file/d/1nmc44s3pKbi_taWDJagPgGrt51yTdMC9
Distributed Inference
Dolphin Inference Network V1 launch thread https://x.com/dphnAI/status/1978158402431041657
Sharded distributed inference over the internet Technical Report https://drive.google.com/file/d/1bznh6BTESNTKA9Itvt-gOG05E4R6SBLx